SQLD 2과목
SQL 기본 및 활용
변경 - Top N 쿼리, 계층형 질의와 셀프 조인, PIVOT절과 UNPIVOTS절, 정규 표현식
제거 - 옵티마이저와 실행계획, 인덱스 기본, 조인 수행 원리
1. 데이터베이스와 DBMS
구성요소 : 계정, 테이블, 스키마
특징 : 빠름, 신뢰성 좋음, 데이터 무결성 보장, 스키마 수정 어려움, 부하 분석 어려움
데이터 무결성 : 데이터의 정확성과 일관성을 유지하고, 데이터에 결손과 부정합이 없음을 보증하는 것
종류 : 개체 무결성, 참조 무결성, 도메인 무결성, NULL 무결성, 고유 무결성, 키 무결성
튜플 = 행 = 인스턴스
ERD : 엔터티, 관계(릴레이션), 속성(ATTRIBUTE)
SELECT : 순서 FROM 부터 SELECT → ORDER BY
#순서 생각하면서 문제 풀 것
| DDL | CREATE, ALTER, DROP, TRUNCATE |
|---|---|
| DML | INSERT, DELETE, UPDATE, MERGE |
| DCL | GRANT, REVOKE |
| TCL | COMMIT, ROLLBACK |
| DQL | SELECT |
ALIAS : 공백, 특수문자, 대소
FROM절 : 오라클 ALIAS 생략 불가
1
MSSQL FROM절이 필요없으면 생략 가능
비절차적 데이터 조작어: 사용자가 무슨 데이터를 원하는 지만을 명세
절차적 데이터: 어떻게 접근해야 하는 지 명세 예) PL / SQL, T-SQL
| DROP | TRUNCATE | DEL | |
|---|---|---|---|
| 롤백 | X | X | O |
| Auto Commit | O | O | X |
| 메모리 | X | X | O |
2. 함수
단일행 함수 / 복수행 함수
입출력 값의 타입에 따른 함수
LOWER(대상) UPPER(대상) SUBSTR(대상, M, N ) M시작위치(+,-) , [N개의 문자열 추출] INSTR(대상, 찾을 문자열, M, N) default = 1, M시작위치, N번쨰 발견 LTRIM(대상, 삭제문자열) RTRIM(대상, 삭제문자열) TRIM(대상) : 오라클은 공백만 삭제 가능 LPAD(대상, N, 문자열) RPAD(대상, N, 문자열) 총 길이N개 CONCAT(대상1, 대상2) LENGTH(대상) 1부터 시작 REPLACE(대상, 찾을문자열, 바꿀문자열) TRANSLATE(대상, 찾을문자열, 바꿀문자열) TRANSLATE(’ABBA;, ‘AB’, ‘ab’) -? 빈문자열 전달시 null 리턴 숫자형 함수
| ABS() | | | — | — | | ROUND(숫자, 자리수) | TRUNC(숫자, 자리수) | | SIGN() | | | FLOOR() : 내림 | CEIL() :올림 | | MOD(1,2) : 나머지 | | | POWER(M,N) | M의 N제곱 | | SQRT() | 루트값 |
- 1/24/60 = 1분 , 1/24/(60/10) = 10분
날짜형 함수
SYSDATE : 년월일시분초 CURRENT_DATE CURRENT_TIMESTAMP ADD_MONTHS(날짜, N) : 음수면 -N MONTHS_BETWEEN(날짜1, 날짜2) 날짜2가 작으면 -리턴 LAST_DAY(날짜) NEXT_DAY(날짜, N) : 1일요일 ROUND(날짜, 자리수) TRUNC(날짜, 자리수) : 월 이전자리 - 변환 함수 : TO_NUMBER, TO_CHAR, TO_DATE, CAST(대상 AS 데이터타입)
- SQL → CONVERT(포맷 전달 시)
- 그룹 함수 = 다중행 함수 (NULL무시하고 연산)
- COUNT, SUM, AVG, MIN, MAX, VARIANCE(분산리턴), STDDEV
- SQL → VAR, STDEV
일반 함수 = NULL 치환 함수
DECODE(대상, 값1, 리턴1, ….) NVL(대상, 치환값) NVL2(대상, 치환값1, 치환값2) NULL = 치환값2 ELSE 치환값1 COALESCE(대상1, 대상2,…) 대상 ≠ NULL 리턴 CASE문
3. WHERE
LIKE 연산자
NOT 연산자 : NOT IN, NOT BETWEEN A AND B, NOT LIKE, NOT NULL
GROUP BY : 데이터가 요약되므로 요약되기 전 데이터와 함께 출력할 수 없음
4. 조인
- ORACLE표준은 테이블 나열 순서 중요하지X,
- ANSI표준은 OUTER JOIN시 순서 중요
종류
- 조건
- EQUI JOIN(등가 JOIN)
NOT EQUI JOIN :
비교 조건이 ‘<’, BETWEEN A AND B 와 같이 ‘=’ 조건이 아닌 연산자를 사용하는 경우의 조인조건
- 조인 결과
- INNER JOIN
- OUTER JOIN
- LEFT/ : 우측 값에서 같은 같이 없는 경우 NULL 값으로 출력
- RIGHT/
- FULL : ORACLE 표준에는 없음
- 두 테이블 전체 기준으로 결과를 생성하여 중복 데이터는 삭제 후 리턴
- LEFT OUTER JOIN 결과와 RIGHT OUTER JOIN 결과의 UNION 연산 리턴과 동일함
- NATURAL JOIN : 자연 연결, 데이터 타입이랑 같아야 함
- USING, ON, WHERE 절에서 조건 정의 불가
- CROSS JOIN : 카티시안 곱 발생
- SELF JOIN
표준조인 : ANSI 표준으로 작성되는 INNER JOIN, CROSS JOIN, NATURAL JOIN, OUTER JOIN을 말함
ON절 : 컬럼명이 다르더라도 사용 가능 , 별칭O, 조건 명시
- ORACLE표준은 FROM절에 테이블을 컴마로 구분, WHERE절에 조인 조건 나열
- ORACLE은 INNER JOIN이 기본 조인 연산이므로 별도의 문법 존재 안함
USING 조건절 : 조인할 컬럼명이 같을 경우 사용 **
- Alias 나 테이블 이름 같은 접두사 붙이기 불가
- 괄호 필수
5. 서브쿼리
GROUP BY절 사용 불가
종류
- 스칼라 서브쿼리 : SELECT
- 하나의 컬럼처럼 사용하기 위해 주로 사용
- 연관 서브쿼리 : 서브쿼리가 메인 쿼리 컬럼 포함하는 형태
- 비연관 서브쿼리 : 서브쿼리가 주로 메인쿼리에 값 제공하는 목적
- 인라인뷰 : FROM
- 테이블처럼 사용하기 위해 주로 사용
- WHERE절
- 비교 상수 자리에 값을 전달하기 위한 목적으로 주로 사용(상수항의 대체)
- 단일행 : 부등호 비교만 가능
- 다중행 : IN / >ANY / <ANY / <ALL / >ALL / SOME/ EXIST
예제) ALL과 ANY 비교
ALL(2000, 3000) : 최대값(3000)보다 큰 행들 반환 < ALL(2000, 3000) : 최소값(2000)보다 작은 행들 반환 ANY(2000, 3000) : 최소값(2000)보다 큰 행들 반환 < ANY(2000, 3000) : 최대값(3000)보다 작은 행들 반환
- 비교 상수 자리에 값을 전달하기 위한 목적으로 주로 사용(상수항의 대체)
다중컬럼 서브쿼리
- 서브쿼리 결과가 여러 컬럼이 리턴
- 조건절에 여러 컬럼 동시 비교, 비교 컬럼수 위치 동일해야함
- 메인쿼리와의 비교 컬럼이 2개 이상
- 대소 비교 전달 불가(두 값을 동시에 묶어 대소비교 할 수 없음)
서브 쿼리 주의 사항
- 특별한 경우(TOP-N 분석 등)을 제외하고는 서브 쿼리절에 ORDER BY절을 사용 불가
- 단일 행 서브쿼리와 다중 행 서브쿼리에 따라 연산자의 선택이 중요
집합 연산자
- 두 집합의 컬럼이 동일하게 구성되어야 함(데이터 타입, 순서, 컬럼 수)
- 합집합 : UNION, UNION ALL (중복O)
- 교집합 : INTERSECT = NOT EXISTS ( A MINUS B)
- 차집합 : MINUS, 순서 중요
- EXCEPT = NOT IN / NOT EXISTS
1 : 1관계 UNION 동일 UNION ALL 2배 INTERSECT 동일 MINUS 공집합
순수 관계 연산자
- SELECT → WHERE
- PROJECT → SELECT
- JOIN → JOIN
- DIVIDE → x
6. 그룹 함수 : COUNT, SUM, MIN, MAX, AVG, VARIANCE, STDDEV
- 반드시 한 컬럼만 전달해야 함, NULL 무시하고 연산함
- GROUP BY FUNCTION : 여러 GROUP BY결과를 동시에 출력(합집합)하는 기능
- GROUPING SETS(A,B.. ) : 그룹 연산 결과 출력, 순서 중요하지 X, 기본 출력에 전체 총계는 출력되지 X , NULL 혹은 () 사용하여 전체 총 합 출력 가능
- ROLLUP(A,B) : 전체 그룹 연산 결과 + 전체 총 계 = UNION ALL로 대체O
- CUBE(A,B) : A별, B별, (A,B)별, 전체 그룹 연산 결과 + 전체 총 계, 순서중요X = UNION ALL로 대체O
- CUBE(A,B) = GROUPING SETS((A),(B),(A,B),())
- 괄호 사용하면 통합 집계
- GROUPING SETS((A, B)) : A로 먼저 그룹화 정렬 한 후 B도 나열 ,AAA BCD
7. 윈도우 함수 : 서로 다른 행의 비교나 연산을 위해 만든 함수, 그룹 연산O
LAG, LEAD, SUM, AVG, MIN, MAX, COUNT, RANK
- PARTITION BY 절
- ORDER BY 절 : 누적값 출력 시 사용, RANK의 경우 필수(정렬 컬럼 및 정렬 순서에 따라 순위 변화)
- ROWS[RANGE BETWEEN A AND B] : 연산 범위 설정 - ORDER BY절 필수
PARTITION BY, ORDER BY, ROWS…절 전달 순서 중요(ORDER BY를 PARTITON BY 전에 사용 불가)
전체를 출력하는 컬럼과 그룹함수 결과는 함께 출력할 수 없음
OVER절을 사용하여 윈도우 함수로 사용 가능
1
2
3
SELECT SUM(대상) OVER([PARTITION BY 컬럼]
[ORDER BY 컬럼 ASC|DESC]
[ROWS|RANGE BETWEEN A AND B]);
윈도우함수의 연산 범위: 집계 연산 시 행의 범위 설정 가능
- ROW : 값이 같더라도 각 행씩 연산
- RANGE : 같은 값의 경우 하나의 RANGE로 묶어서 동시 연산(DEFAULT)
- BETWEEN A AND B
- A : CURRENT ROW , UNBOUNDED PRECEDING, N PRECEDING
- B : CURRENT ROW, UNBOUNDED FOLLOWING, N FOLLOWING (N 이후까지 )
8. 순위 함수
- RANK(순위) : 윈도우 함수X → 일반 함수
- RANK() OVER() : ORDER BY 필수
- DENSE_RANK : 누적 순위, 동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식
- ROW_NUMBER : 연속된 행 번호, 단순히 순서대로 나열한대로의 순서 값 리턴
- LAG(이전 값), LEAD(이후 값) : ORDER BY 필수
- FIRST_VALUE, LAST_VALUE : 순서와 범위 정의에 따라 최솟값과 최댓값 리턴 가능
1
2
3
4
5
6
7
8
9
10
11
12
SELECT ENAME, DEPTNO, SAL,
FIRST_VALUE(SAL) OVER
(PARTITION BY DEPTNO ORDER BY SAL) AS MIN_VALUE,
FIRST_VALUE(SAL) OVER
(PARTITION BY DEPTNO ORDER BY SAL DESC) AS MAX_VALUE
FROM EMP;
SELECT ENAME, DEPTNO, SAL,
LAST_VALUE(SAL) OVER
(PARTITION BY DEPTNO ORDER BY SAL) AS MAX_VALUE
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS MAX_VALUE
- NTILE : 행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위함 함수
- 그룹 번호가 리턴됨 - ORDER BY 필수 -
- PARTITION BY를 사용하여 특정 그룹을 또 원하는 수 만큼 그룹 분리 가능
비율관련 함수
- RATIO_TO_REPORT : 각 값의 비율 리턴, ORDER BY X
- CUME_DIST : (행의)누적비율, ORDER BY를 사용하여 누적비율을 구하는 순서 정할 수 있음
- PERCENT_RANK : PERCENTILE(분위수) 출력, 전체 COUNT중 상대적 위치 출력(0~1 범위 내), ORDER BY 필수
9. TOP N QUERY
페이징 처리, 전체 결과에서 특정 N개 추출
추출 방법 1. ROWNUM 2. RANK 3. FETCH
ROWNUM : 행 번호, 가상의 번호라 연산 불가, 정렬 순서에 따라 출력되는 ROWNUM이 달라짐
연산 X 연산 O ‘=’ EQUAL + ‘<’ : 1부터 순서대로 뽑을 수 있기 때문에 출력 가능함. ‘>’ 0 오류 코드 : WHERE ROWNUM BETWEEN A AND B
FETCH절 : 출력될 행의 수를 제한하는 절 , 오라클 12C이상, SQL-SEVER, ORDER BY 절 뒤에 사용
1 2 3
ORDER BY OFFSET N { ROW | ROWS } FETCH { FIRST | NEXT } N { ROW | ROWS } ONLY
- OFFSET : 건너뛸 행의 수
- N : 출력할 행의 수
- FETCH : 출력할 행의 수를 전달
- FIRST : OFFSET 안썼을 때 처음부터 N 행 출력 명령
- NEXT : OFFSET을 사용했을 경우 제외한 행 다음부터 N행 출력 명령
ROW ROWS
TOP(2) WITH TIES 컬럼명: 동일한 값 있으면 써야 함
10. 계층형 질의
하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층(depth)을 표현하는 기법
- PRIOR의 위치에 따라 연결하는 데이터 달라짐
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
```sql
SELECT
FROM
**START WITH** 시작 조건
**CONNECT BY PRIOR** 연결조건 [AND 연결조건...]
**가상 컬럼**
- LEVEL : 각 DEPTH를 표현 (1부터)
- CONNECT_BY_ISLEAF : LEAF NODE(최하위노드) 여부 (참1 거짓0)
**가상 함수**
- CONNECT_BY_ROOT 컬럼명 : 루트노드의 해당 컬럼명의 값이 출력
- SYS_CONNECT_BY_PATH(컬럼, 구분자) : 이어지는 경로 출력
- ORDER SIBLINGS BY 컬럼 : 같은 레벨일 경우 정렬 수행
```
데이터 구조 1. LONG DATA : 행 2. WIDE DATA : 열
- PIVOT : LONG → WIDE
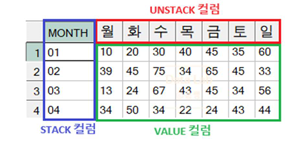
- FROM절 : STACK, UNSTACK, VALUE 컬럼명만 정의 필요
- PIVOT절에서 선언한 VALUE컬럼, UNSTACK컬럼을 제외한 모든 컬럼은 STACK컬럼이 됨
- PIVOT절 : UNSTACK, VALUE 컬럼명 정의, IN 연산자에 UNSTACK 컬럼 값을 정의
1
2
3
4
5
6
SELECT * FROM 테이블명 OR 서브쿼리
PIVOT (VALUE 컬럼명 FOR UNSTACK 컬럼명 IN (값1, 값2..));
SELECT *
FROM (SELCT EMPNO, DEPTNO, JOB FROM EMP)
PIVOT (COUNT(EMPNO) FOR DEPTNO IN (10, 20, 30));
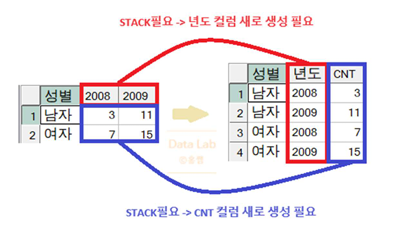
- UNPIVOT : WIDE → LONG
- STACK 컬럼: 이미 UNSTACK되어 있는 여러 컬럼을 하나의 컬럼으로 STACK시 새로 만들 컬럼이름
- VALUE컬럼 : 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명
- 값1, 값2… : 실제 UNSTACK 되어 있는 컬럼이름들
11. 정규 표현식
| d : 0~9 | D | [ab] : a 또는 b의 한 글자 | [^ab] |
|---|---|---|---|
| s : 공백 | S | [A-Z] | [a-z] |
| w : 단어 | W | [A-z] | [0-9] |
| t : tab | n | i+ : i가 1회 이상 반복 | i* : i가 0회 이상 반복 |
| ^ : 시작되는 글자 | $ | i{n} : i가 n회 반복 | i{n1,n2} |
| [:punct:] : 특수문자 | [:xdigit:] : 16진수 | {} : 그룹지정 | n |
REGEXP_REPLACE =REGEXP_COUNT : 정규식 표현을 사용한 문자열 치환 기능,
REGEXP_SUBSTR : 정규식 표현을 사용한 문자열 추출,
- 추출그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호
1
2
3
4
5
6
7
8
9
10
**REGEXP_REPLACE**(대상, 찾을문자열, [바꿀문자열],
[검색위치], [발견횟수 default 0], [옵션])
**REGEXP_COUNT**(원본, 찾을문자열,
시작위치, [옵션])
**REGEXP_SUBSTR**(대상, 찾을문자열, [바꿀문자열],
[검색위치], [발견횟수 default 1], [옵션])
**REGEXP_INSTR**(원본, 찾을문자열, [시작위치 default 1],
[발견횟수 default 첫 문자열 위치])
**REGEXP_LIKE**(원본, 찾을문자열, [옵션])
*시작위치, 추출개수 인수 없음
- 바꿀문자열 생략 시 문자열 삭제
- 검색위치 DEFAULT 1
- -c : 대소 구분, -i : 대소 구분X, -m : 패턴을 다중라인으로 선언 가능
- \d : 한 자리수의 숫자, \d+ : 연속적인 숫자
12. DML(DATA Manipulation Language) : 삽입, 수정, 삭제, 병합(merge)
- insert : 한 번에 한 행만(sql은 여러행 가능)
- INTO절에 컬럼명을 명시하여 일부 컬럼만 입력 가능. 작성하지 않은 컬럼은 NULL 이 입력됨 ☞ NOT NULL 칼럼의 경우 오류 발생
- update : 컬럼 단위 , 다중 컬럼 수정 가능
- delete : delete[from]테이블명 [where 조건];
delete from 테이블명;: 전체 삭제
- merge : 참조 테이블과 동일하게 맞추는 작업(참조테이블의 데이터 입력, 참조테이블의 값으로 수정 등) ☞ INSERT, UPDATE, DELETE 작업을 동시에 수행
1
2
3
4
5
6
7
8
MERGE INTO 수정할 테이블명
USING 참조테이블
ON **(연결조건) -> 괄호 필수**
WHEN MATCHED THEN
UPDATE
SET 수정할 내용
WHEN NOT MATCHED THEN
INSERT VALUES(삽입할내용)
13. TCL(Transcation Control Language) : COMMIT, ROLLBACK,
- 작업단위(트랜잭션) 별로 제어,
- DML 수행 후 트랜잭션 정상 종료 X → LOCK 발생
- 트랜잭션
- 원자성(atomicity) : all or nothing
- 일관성(consistency)
- 고립성(isolation) : 다른 트랜잭션 영향X
- 지속성(durability) : 영구적 저장
- COMMIT : 되돌릴 수 없음, 오라클은 DDL 오토커밋
- ROLLBACK : ROLLBACK TO savepoint_name; - 최종 COMMIT 지점/변경 전/특정 SAVEPOINT 지점으로 원복됨
- SAVEPOINT : SAVEPOINT 이름;
- 문제
- Dirty-Read : 수정, 커밋 아직X
- non-repeatable read : 같은 쿼리 2번 실행 시 값이 다름
- Phantom read : 같은 쿼리 유령레코드가 두번
14. DDL(Data Definition Language) :객체 생성, 삭제, 변경
- CREATE : 테이블명, 컬럼명, 컬럼순서, 컬럼크기, 컬럼의 데이터타입 정의 필수, 소유자 명시 가능,
- 복제 테이블은 기존 테이블에 있는 제약조건, INDEX 등은 복제되지 X
- ALTER : 컬럼순서 변경 불가(재생성으로 해결), 여러 컬럼 동시 추가 가능(반드시 괄호 사용, NOT NULL 속성 X, DEFAULT 선언 시 NOT NULL 속성을 갖는 컬럼 추가 가능)
- NOT NULL 선언 시 제약조건 생성이 아닌 컬럼 수정(MODIFY)으로 해결
- DROP : 데이터와 구조를 동시 삭제, 즉시 반영(롤백 불가)
- TRUNCATE : 구조 남기고 데이터만 즉시 삭제, 즉시 반영(롤백 불가) ,
- RECYCLEBIN에 남지 않음
KEY
- PRIMARY KEY : 유일성, 최소성, 하나의 테이블에 여러 기본키 생성X, UNIQUE INDEX
- UNIQUE : 중복 X, NULL O, UNIQUE INDEX
- FOREIGN KEY : 반드시 참조(부모)테이블의 참조 컬럼(REFERENCE KEY)이 사전에 PK 혹은 UNIUQE KEY를 가져야 함
- CHECK : 직접적으로 데이터의 값 제한 ( );
VIEW : 단순뷰, 복합뷰
특징 : 가상, 저장공간X, 안전, 다른 뷰의 기초, 테이블 삭제 시 자동 삭제
장점 : 논리적 독립성, 보안유지, 관리 단순화, 다양한 지원
단점 : 정의 변경 불가, 삽입, 삭제, 갱신 연산에 제한, 인덱스X
1 2 3 4
CREATE [OR REPLACE] VIEW 뷰이름 AS 조회 쿼리 ; DROP VIEW 뷰명;
SEQUENCE : 자동으로 연속적인 숫자 부여
1 2 3 4 5 6 7
CREATE SEQUENCE 시퀀스명 INCREMENT BY (DEFAULT 1) START WITH (DEFAULT 1) MAXVALUE MINVALUE CYCLE | **NOCYCLE** -> 시퀀스 번호 재사용 CACHE N (DEFAULT 20);
시노님(SYNONYM) : 테이블 별칭 생성
CREATE [OR REPLACE] [PUBLIC] SYNOYM 별칭 FOR 테이블명;# DCL(DATE Control Language)
권한 : 원칙 조회 불가, 테이블 조회, 수정 권한 부여 가능
- 오브젝트권한 : 테이블에 대한 권한
- 시스템권한 : 테이블생성, 인덱스 삭제 등
1 2 3 4 5
GRANT 권한 ON 테이블명 TO 유저; REVOKE 권한 ON 테이블명 FROM 유저; CREATE ROLE 롤이름 GRANT SELECT ON 테이블명 TO 롤이름; GRANT 롤이름 TO 테이블명;
- WITH GRANT OPTION : 오브젝트 권한을 다른 사용자에게 부여,
- 중간관리자만 회수 가능
- 중간관리자에게 부여된 권한 회수 시 제 3자에게 부여된 권한도 함께 회수됨
- WITH ADMIN OPTION : 시스템 권한/롤 권한을 다른 사용자에게 부여,
- 직접 회수 가능
- 중간관리자에게 부여된 권한 회수 시 제 3자에게 부여된 권한은 남아있음
15. SQL-Server
- 여러 개의 컬럼을 동시에 수정하는 구문 지원X
- ALTER Not null default 아님 (새로 선언해줘야 함)
16. NULL
- 모르는 값, 값의 부재, Null과 비교시 알수없음 반환
- 공집합X, 공백X, 0 X
- 사칙연산 = NULL , “ “ = NULL
- NULL 비교는 오직 IS NULL / IS NOT NULL만 가능
17. PL / SQL
프로시저, 트랜잭션, USER DEFINED , 트리거
- Block구조 → 각 기능별 모듈화 → 통신량 낮음
- 변수, 상수 등 선언
- IF, LOOP 절차형 언어
- DBMS 정의 에러, 사용자 정의
- 오라클 내장
- 응용 프로그램 성능 높음
| 프로시저 | 트리거 |
|---|---|
| CREATE | CREATE |
| EXECUTE 명령어 | 자동 |
| TCL O | TCL X |